...
As you can imagine based on the name, linked data is all about references (links or "pointers") between entities (pieces of data). In principle:
All entities (resources in the linked data jargon) in the data are named with URIs (Uniform Resource Identifier).
The names should in most cases be HTTP(S) URIs, as this allows a standardized way to resolve the names (i.e. access the resources).
When a client resolves the name, relevant information about the resource should be provided (to the extent depending on the access rights the resolving party has). This means for example, that a human user receives an easily human-readable representation of the resource, while a machine receives a machine-readable representation of it.
The resources should refer (be linked) to other resources when it aids in discoverability, contextualizing, validating, or otherwise improving the useability of the data.
How to Name Things
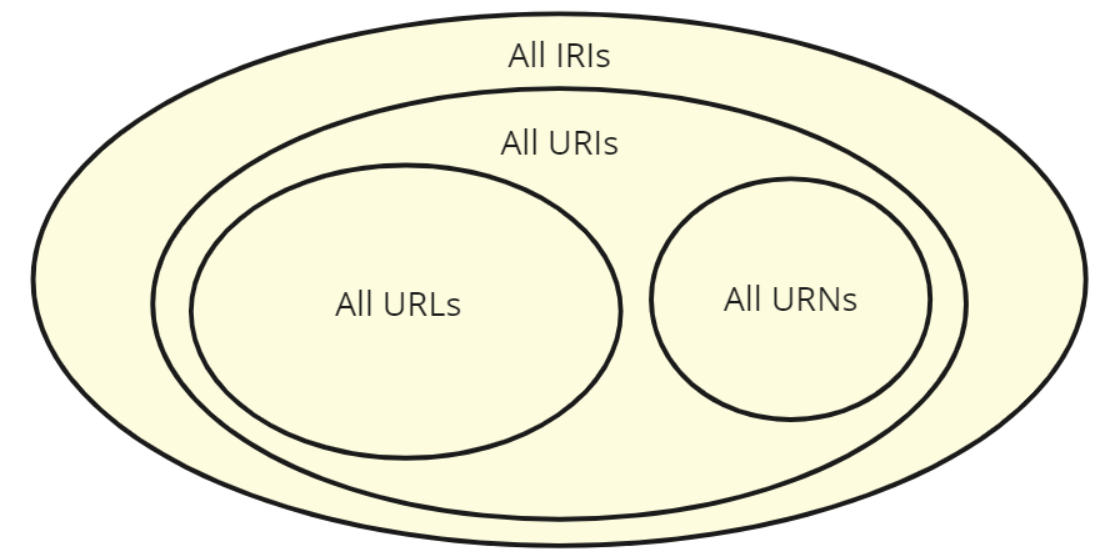
As mentioned, all resources are named ("minted") with URI/IRI identifiers, which we can then use to refer to them when needed. URLs and URNs form subsets of URIs (which in turn is a subset of all IRIs), so any URL - be it for an image, web site, REST endpoint address or whatever - is already ready to be incorporated to the linked data ecosystem. URNs (e.g. urn:isbn:0-123-456-789-123) can be used as well, but unlike the aforementioned URLs they can't be directly resolved. URNs with their own sub-namespaces have specific use cases (ISBN, EAN, DOI, UUID etc.) where they are preferred, but in general you should aim towards creating HTTP URIs (or to be more precise HTTP IRIs as explained later). The difference between an URL and HTTP URI/IRI is that the first is an address for locating something whereas the latter conceptually acts also as an identifier for naming it.
There is a deep philosophical difference and reasons between how and what things are named in linked data compared to traditional data modeling e.g. with UML, but covering this requires going through some elementary principles first. We won't go deeply into the conceptual basis of URIs in this text, but the most important thing to keep in mind is: URLs only point to resources on the Web, whereas URIs are meant to describe any resources - also abstract or real-world ones. As an example, Finland as a country is not a resource created specifically and existing only on the Web, but it can still be named with a HTTP URI/IRI so that it can be described in machine-readable terms and used in information systems.
When you mint a new HTTP URI/IRI for something, you can give it any name that adheres to to RFC 3986, but as parts of the HTTP namespace are controlled (owned) by different parties, it is not a good principle to name things in namespaces owned by someone else unless specifically given permission. As an example, the
The FI-Platform gives every resource
...
an IRI name in the form of <https://iri.suomi.fi/model/modelName/versionNumber/localName>
This keeps , keeping all the resources neatly inside the each model's own versioned namespace (the https://iri.suomi.fi/model/modelName/versionNumber/ part). On the other hand, naming resources <https://suomi.fi/localName> would not be a good idea, as resolving these addresses is controlled by the DVV web server, resulting in either unresolved (HTTP 404) or clashes with other content already being served by the same URL. You can think of the localName part of the URI IRI as identical to the local names of XML or UML elements. The namespace is a core part of XML and UML schemas as well, but in (HTTP URI IRI based) linked data each element is referred to with a global identifier - thus making it unambiguous to know which element we are talking about even if two elements have the same local names.
How do we then identify what the local name part of the URI is? There are two methods, but both require that you follow the RFC:s correctly. There is a multitude of ways both users and Web services use malformed URIs, and browsers and web servers encourage this kind of behaviour by autocorrecting many malformed URIs before the request is sent or when it is received. . A common method is to use the URI fragment # to distinguish the namespace from the local name, but a more flexible, less problematic way (also used by the FI-Platform) is to simply use slash / and split the URI from the rightmost slash.
the format shown above is called a raw URI, but when looking at linked data serializations, you might stumble upon a familiar representation from XML: namespaceName:localName. This is called a CURIE (Compact URI Expression), where the namespace is given a shorter easier to read name and it is concatenated with the local name with a colon. This only aids the human-readability of the serializations, and requires that you always keep the context (namespace names to namespace URI mappings) with the data. Otherwise you will end up with unusable data if you combine CURIE form datasets that use colliding namespace names for different namespace URIs. This is not a problem when managing linked data with software, only when editing it manually.
...
If you are managing data that you intend to distribute/share/transfer to other parties, it is good to adhere to the rule that all resources are given HTTP URI names from a namespace (domain or IP address) that a) you control and b) are resolved to something meaningful.There There is an exception though: if all the information is a) managed in a siloed environment and b) can be represented explicitly as linked data requiring no resolving, you can freely use any URIs you wish without worrying about them resolving to anything nor conflicting with existing URIs outside your environment. This means that you can also mint URIs for resources before you have a framework ready for resolving them.
Linked Data is Atomic
You should use primarily IRIs for naming all entities you create and only use namespaces that are under your control.
You should always publish your models and data with versioned URI identifiers to avoid unintended side-effects.
Linked Data is Atomic
It is crucial to understand that by nature, linked data is atomic and always in the form of a graph. The lingua franca of linked data is RDF (Resource Description Framework), which allows for a very intuitive and natural way of representing information. In RDF everything is expressed as triples (3-tuples): statements consisting of three components (resources). You can think of triples as simply rows of data in a three column data structure: the first column represents the subject resource (from whose point of view the statement is made), the second column represents the context resource of what is being stated by the subject, and the third column represents the object or value resource of the statement. Simplified to the extreme, "Finland is a country" is a statement in this form:
...
The triples in this dataset can be serialized very simply as three triples each consisting of three resources, or represented as a three column tabular structure:
| subject resource | predicate resource | object resource |
|---|---|---|
<https://finland.fi/> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> |
|
<https://finland.fi/> | <https://datamodel/hasNumberOfLakes> |
|
<https://finland.fi/> | <https://datamodel/hasCapital> |
|
As you can see, the model consists of only atomic parts with nothing inside them. Linked data is structural: the meaning of every resource is only defined by how it is related to other resources. We can say that conceptually it is the resource <https://finland.fi/> that contains the number of lakes or its type, but on the level of data structures, there is no containment. This is in stark contrast to typical data modeling paradigms, where entities are specified as templates or containers with mandatory or optional components. As an example, UML classes are static in the sense that they cannot be expanded to cover facets that were not part of the original design. On the other hand, we can expand the resource <https://finland.fi/> to have an unlimited amount of facts, even conflicting ones if our intention is to compare or harmonize data between datasets. We could for example have two differing values for the number of lakes with additional information on the counting method, time and responsible party in order to analyze the discrepancy.
Linked Data Can Refer to Non-Linked Data
Note that triples are directional. So if our dataset or model points to an object resource somewhere on the Web, that resource has no idea of our model existing or associating itself with it. But, we are naturally able to use those external resources at any position in the triples of our graph: we could even take a resource and speak with "its mouth". As an example, we could take the (pretty much universally used) definition of a class from the OWL vocabulary residing at at <http://www.w3.org/2002/07/owl#Class> and state novel facts about it. This in general is not recommended, but in specific use cases it can be extremely beneficial to be able to expand outside resources with new facts (on the other hand there are more sophisticated tools offered by e.g. OWL for achieving the same ends).
In a nutshell:
All data and models are graphs defined as triples.
It is always possible to expand graphs by adding triples pointing to new resources or to state facts about the external world.
Linked Data Can Refer to Anything
You might have already guessed that You might have already guessed that this kind of graph data structure becomes cumbersome when it is used for example to store lists or arrays. Both are possible in RDF, but the flexibility of linked data allows us to leverage the fact that the same URI can offer us a large dataset e.g. in JSON format with the proper content accept type, while using the same URI as the identifier for the dataset and offer relevant RDF description of it. Additionally, e.g. REST endpoint URLs that point to individual records or fragments of a dataset can also be used to allow us to talk about individual dataset records in RDF while simultaneously keeping the original data structure and access methods intact. The URL based ecosystem does not have to be aware of the semantic layer that is added on top or parallel to it, so implementing linked data based semantics to your information management systems and flows is not by default disruptive.
Let us take an example: you might have a REST API that serves photos as JPEGs with a path: https://archive.myserver/photos/localName. When doing a HTTP request with Accept headers for image/jpeg, the URI will resolve a JPEG, but when using Accept header for application/ld+json, the same URI would resolve to a semantic RDF representation in JSON-LD of the photo (for example of its location, time and other EXIF data as well a provenance etc.).
What about models then?
Everything Has an Identity
...